
Bei der 2. Pimcore User Group | Berlin widmeten sich mehr als 50 Teilnehmer ganz dem Thema "Pimcore Enterprise", seinen Unterschieden zur Community Edition und den zusätzlichen Möglichkeiten, die es für die Verwaltung von Assets bietet.
Pimcore Enterprise Platform: Business Assets in großem Maßstab verwalten
Pimcore und Open-Source gehören einfach zusammen. Aber Open-Source ist nicht immer die richtige Lösung für ein Projekt. Compliance-Anforderungen, die Nachfrage nach speziellen Dienstleistungen wie Langzeit-Support oder der Bedarf an bestimmten vorinstallierten Funktionen, es gibt eine Vielzahl von Gründen, die den Einsatz von proprietärer Software erfordern können.
Auf der zweiten Pimcore User Group | Berlin am 21. Juni widmeten sich daher mehr als 50 Teilnehmer ganz dem Thema "Pimcore Enterprise", seinen Unterschieden zur Community Edition und den zusätzlichen Möglichkeiten, die es für die Verwaltung von Assets bietet.
Pimcore Enterprise Edition - Vorteile und Unterschiede zur Community Edition

Stefan Gruber ist Chief Sales Officer bei Pimcore und berät seit mehr als 15 Jahren Unternehmen bei Marketingkampagnen und Digitalisierungsprojekten. Er kennt die Anforderungen an Customer-Experience-Plattformen und natürlich auch die Vorteile von Pimcore wie kein anderer.
In seinem Vortrag erläuterte er die exklusiven Features der Pimcore Enterprise Edition und gab einen Einblick in die Pimcore-Roadmap und die für die Zukunft geplanten Features. Für viele Teilnehmer war dies ein Highlight, da diese Informationen bisher nur den Pimcore-Partnern zugänglich waren.
Stefans Top-3 Features der Portal Engine in Pimcore Enterprise
- Eine sofort einsatzbereite Elasticsearch Integration
- Download Cart zum Export ausgewählter Assets in großen Mengen
- Analysefunktionen mit konfigurierbaren Berichten
Danke, Stefan, für deine Einblicke und dass du dir die Zeit genommen hast, die Fragen der Community zu beantworten!
Reality Check: Vektorbasierte Suche im Unternehmensmaßstab mit ChatGPT und Pimcore

Christoph Lühr ist CTO bei Basilicom und ein Pimconaut der ersten Stunde. Für die Pimcore User Group hat er sich angesehen, wie ChatGPT genutzt werden kann, um Inhalte in Pimcore mit Hilfe einer vektorbasierten Suche noch besser auffindbar zu machen. In seiner Präsentation und Demo macht er den Basilicom Reality Check, um zu sehen, ob das Konzept wirklich funktioniert und ob es in Zukunft eine Alternative zu Tools wie Elasticsearch sein kann.
Für seinen Reality Check wählte Christoph ein "Produkt", das jeder kennt: Filme. Anhand von Daten der IMDb (International Movie Database) zeigte er den Anwesenden, wie die schlagwortbasierte Volltextsuche funktioniert und warum die vektorbasierte Suche diese ergänzen oder sogar ersetzen könnte.
Um das zu demonstrieren, suchte er in IMDb nach "Sherlock" und dann nach "Detective, London". Während die erste Suche überraschenderweise die beliebte Fernsehserie als erstes ergab, waren die Ergebnisse für "Detective, London" enttäuschend. Im Gegensatz zu den meisten Menschen, die den betreffenden Titel aufgrund des Kontexts erraten hätten, muss sich eine Volltextsuche auf die in der Beschreibung verwendeten Schlüsselwörter und Synonyme verlassen.
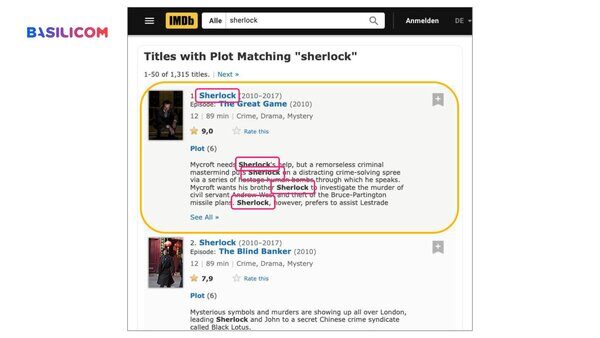
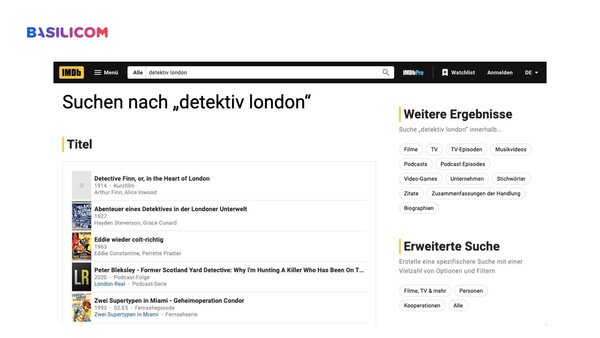
Um dieses Problem zu lösen, hat Christoph seine eigene Suchmaschine mit einer Vektordatenbank entwickelt.
Aber was ist ein Vektor?
Ein Vektor ist eine Dimension, d.h. eine Beziehung zu einer Eigenschaft. Vereinfacht ausgedrückt, ist er die Entfernung zu einer bestimmten Eigenschaft. Beispiele für Vektoren sind Koordinaten, etwa dass Potsdam näher an der Eigenschaft "Berlin" liegt als Stuttgart.
Um bei Filmen zu bleiben: Ein relevanter Vektor für einen Film ist seine Nähe zu einem Genre. Zum Beispiel liegt "Sherlock Holmes" sehr nahe an der Eigenschaft "Krimi", während "Romeo und Julia" weit entfernt ist.

Um nach einem Zusammenhang zu suchen, braucht man jedoch Hunderte, wenn nicht Tausende von Vektoren anstelle von zwei. Eine so große Anzahl von Vektoren kann natürlich nicht effizient von Hand erstellt werden - dazu ist maschinelles Lernen erforderlich, z. B. Large Language Models (LLM) wie ChatGPT für Text.
Die KI kann Konzepte in den Texten erkennen und daraus Vektoren generieren. Diese werden dann in einer Datenbank gespeichert und können später für die Suche verwendet werden. So kann sie beispielsweise aus zwei Namen ableiten, dass es sich bei den Protagonisten um zwei Männer handelt.
Der effizienteste Weg, dies mit ChatGPT zu tun, ist die Verwendung seiner "Embeddings"-API. Einbettungen sind in diesem Zusammenhang nur ein schickes Wort für Vektor.
Vektorbasierte Suche in Aktion
Für den Realitätscheck lud Christoph Filmbeschreibungen aus IMDb auf Pimcore hoch und ließ sie von ChatGPT analysieren. Die KI berechnet automatisch den Abstand zwischen den Vektoren für jede Suche. Je näher das Ergebnis liegt, desto höher wird es für den Nutzer eingestuft. Die Ergebnisse schlagen den Volltext bei weitem.

Ein weiterer Vorteil ist, dass die vektorbasierte Suchmaschine mit jeder Sprache funktioniert, in der das LLM trainiert wurde, auch wenn der Text nur in einer Sprache vorliegt.
Unser Fazit
Basilicom Reality Check? Check! Die vektorbasierte Suchmaschine liefert erfolgreich die relevantesten Ergebnisse für die kontextbasierte Suche und kann mit Pimcore einfach implementiert werden. Da Vektordatenbanken mithilfe von KI automatisch erstellt und aktualisiert werden können, sind sie relativ kostengünstig einzurichten und zu pflegen.
In vielen Fällen ist die Volltextsuche immer noch sinnvoll, zum einen, weil sie kostengünstiger ist (Kosten pro Suche), zum anderen, weil sich die Nutzer im Laufe der Jahre an die Stichwortsuche gewöhnt haben.
Allerdings kann die vektorbasierte Suche eine Alternative sein und ist bereits eine sehr gute Ergänzung, die das Nutzererlebnis deutlich verbessern kann.


