
At the 2nd Pimcore User Group | Berlin, more than 50 participants dedicated themselves entirely to the topic of "Pimcore Enterprise", its differences from the Community Edition and the additional possibilities it offers for managing assets.
Pimcore Enterprise Platform: Managing Business Assets at Scale
Pimcore and open-source simply belong together. But open-source is not always the right solution for a project. Compliance requirements, demand for special services like long-term support, or the need for certain pre-installed functions, there are a multitude of reasons that might require the use of proprietary software.
Therefore, at the second Pimcore User Group | Berlin 21st June, more than 50 participants dedicated themselves entirely to the topic of "Pimcore Enterprise", its differences from the Community Edition and the additional possibilities it offers for managing assets.
Pimcore Enterprise Edition - Advantages and differences to the Community Edition

Stefan Gruber is Chief Sales Officer at Pimcore and has been advising companies on marketing campaigns and digitalization projects for more than 15 years. He knows the demands on customer experience platforms and, of course, the benefits of Pimcore better than anyone else.
In his presentation, he explained the exclusive features of the Pimcore Enterprise Edition and gave us an insight into the Pimcore roadmap, and the features planned for the future. This was a highlight for many attendees as this information was previously only shared with Pimcore partners.
Stefan's Top-3 Features of the Portal Engine in Pimcore Enterprise
- An out-of-the-box Elasticsearch integration
- Download Cart to export selected assets in bulk
- Analytics features with configurable reports
Thanks, Stefan, for your insights and for taking the time to answer the questions of the community!
Reality Check: Vector-based search at Enterprise Scale with ChatGPT and Pimcore

Christoph Lühr is the CTO at Basilicom and a Pimconaut since the very beginning. For the Pimcore User Group, he looked at how ChatGPT can be used to make content in Pimcore even more discoverable with the help of a vector-based search. In his presentation and demo, he does the Basilicom Reality Check to see if the concept really works and if it can be an alternative to tools like Elasticsearch in the future.
For his reality check, Christoph chose a "product" that everyone is familiar with: movies. Using data from the IMDb (International Movie Database), he showed attendees how keyword-based full-text search works and why vector-based search could complement or even replace it.
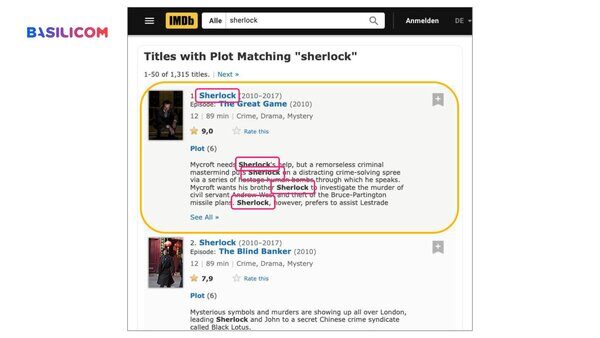
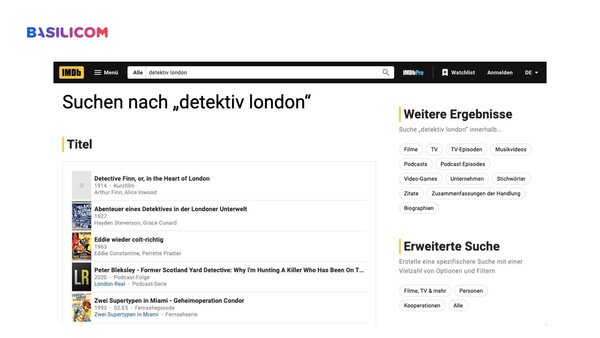
To demonstrate, he searched IMDb for "Sherlock" and then "Detective, London". While the first search unsurprisingly returned the popular TV show first, the results for "Detective, London" were disappointing. Unlike most humans, who would have guessed the title in question based on the context, a full-text search has to rely on the keywords and synonyms used in the description.
To fix this, Christoph created his own search engine using a vector database.
But what’s a vector?
A vector is a dimension, i.e. a relationship to a property. In simple terms, it's the distance to a particular property. Examples of vectors are coordinates, such as Potsdam being closer to the property "Berlin" than Stuttgart.
To stick with movies, a relevant vector for a film is its proximity to a genre. For example, "Sherlock Holmes" is very close to the property "crime fiction", while "Romeo and Juliet" is far away.

To search for a context, however, you need hundreds, if not thousands, of vectors instead of two. Obviously, such a large number of vectors cannot be efficiently created by hand - it requires machine learning, for example, Large Language Models (LLM) such as ChatGPT for text.
The AI can recognize concepts in the texts and generate vectors from them. These are then stored in a database for later use in search. For example, it can infer from two names that the protagonists are two men.
The most efficient way to do this with ChatGPT is to use its "embeddings" API. Embeddings in this context are just a fancy word for vector.
Vector-based search in action
For the reality check, Christoph uploaded film descriptions from IMDb to Pimcore and had them analyzed by ChatGPT. The AI automatically calculates the distance between the vectors for each search. The closer the result, the higher it ranks for the user. The results beat full text by a landslide.

An additional advantage is that the vector-based search engine works with any language the LLM has been trained in, even if the text is only available in one language.
Our Conclusion
Basilicom Reality Check? Check! The vector-based search engine successfully delivers the most relevant results for context-based searches and can be easily implemented with Pimcore. Because vector databases can be created and updated automatically using AI, they are relatively inexpensive to set up and maintain.
In many cases, full-text search still makes sense, partly because it is more cost-effective to run (cost per search) and partly because users have become accustomed to using keyword search over the years.
However, vector-based search can be an alternative option and is already a very good complementary feature that can significantly improve the user experience.

.jpg?width=520&height=294&name=poca-crew(1).jpg)
